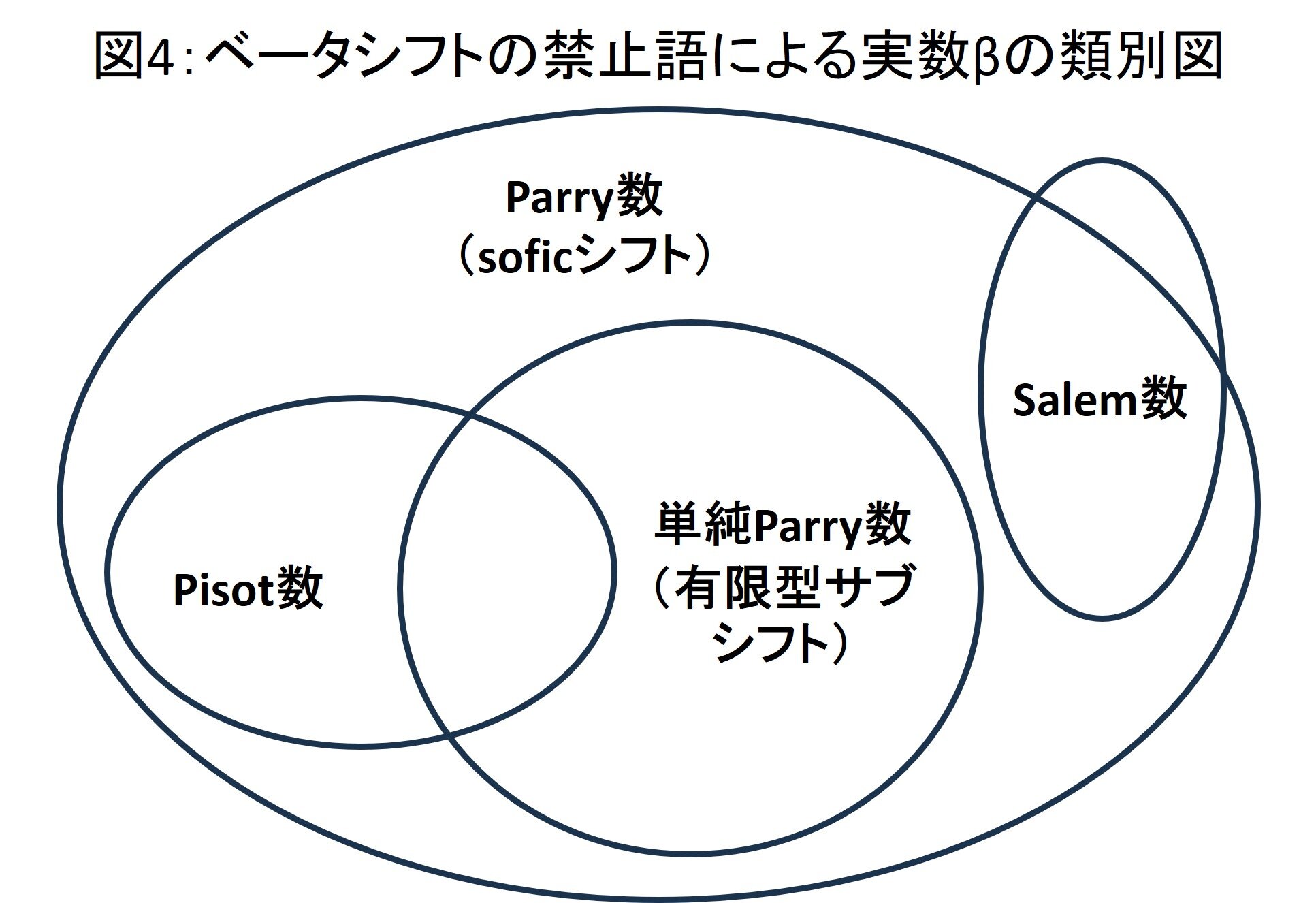
研究課題1:UAVを使った山間部の避難誘導システム
UAV1(複数)は避難者を発見すると避難経路を設定する。 UAV2(複数)は避難経路に沿って安全地帯へと誘導する。土砂崩れ等通行不可状況を発見すると避難経路を更新しつつ誘導する。
| 研究室 | 教員 | 専門分野 |
|---|---|---|
| 神林研究室 | 神林 靖 教授 | 離散数学 計算理論 数理政治学 |
| 熊澤研究室 | 熊澤 努 教授 | ソフトウェア工学 形式的検証技術 モデル検査 |
| 末永研究室 | 末永 敦 教授 | 分子シミュレーション 創薬支援 バイオインフォマティクス |
| 福井研究室 | 福井 一彦 教授 | ヘルス・インフォマティックス バイオ・データサイエンス 医療情報 |
| 矢部研究室 | 矢部 博 教授 | 最適化理論 数理計画法 |
| 溝口研究室 | 溝口 知広 教授 | 3次元大規模環境計測 3次元形状処理 機械学習 |
| 雨宮研究室 | 雨宮 崇之 准教授 | 生命情報学 計算生物学 バイオインフォマティクス |
| 高田研究室 | 高田 寛之 准教授 | 応用確率論:待ち行列理論、確率ネットワーク算法 機械学習:スパースモデリング、システム同定 |
| 神澤研究室 | 神澤 健雄 講師 | 力学系理論 微分方程式論 量子開放系 |
| 藤澤研究室 | 藤澤 健吾 講師 | 統計科学 カテゴリカルデータ解析 多変量解析 |
| 高溝研究室 | 高溝 史周 講師 | 数論 形式言語 フラクタル幾何 |

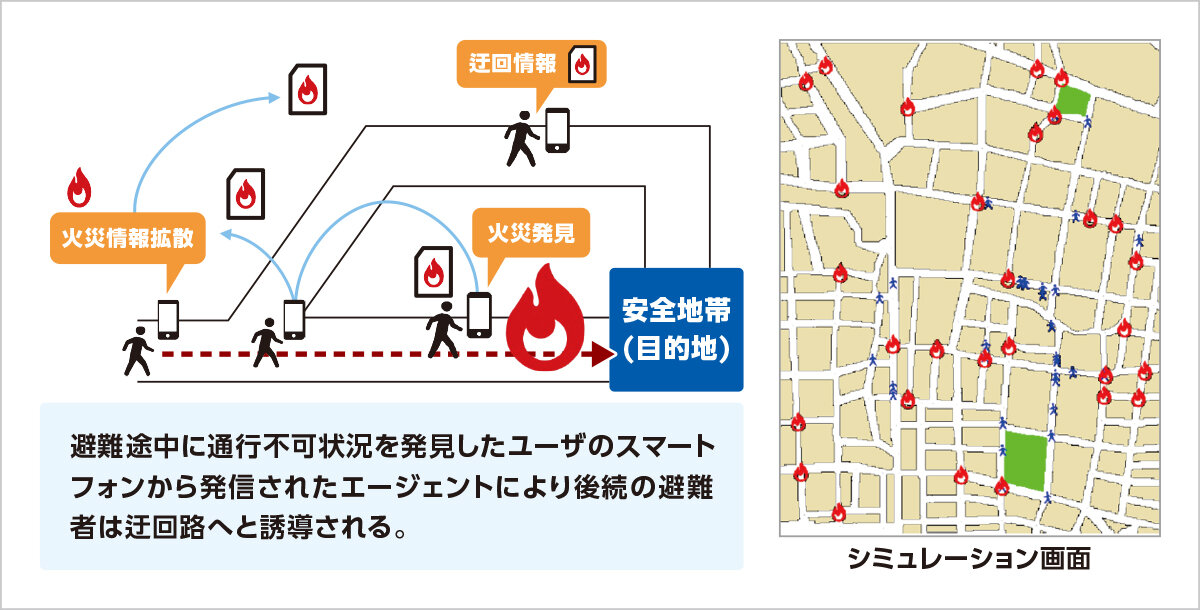
われわれは,エージェント技術により,柔軟な制御ソフトウェアの構築をめざしてしています。エージェントにより並列処理が自然に記述できるだけでなく,アルゴリズムも単純にすることができます。現在取り組んでいるプロジェクトには,スマートフォン間を移動して災害時に情報収集と避難誘導するエージェントシステム,複数のUAVを制御して避難誘導するエージェントシステム,侵入者を検知して追跡する群ロボットを制御するエージェントシステム等があります。
UAV1(複数)は避難者を発見すると避難経路を設定する。 UAV2(複数)は避難経路に沿って安全地帯へと誘導する。土砂崩れ等通行不可状況を発見すると避難経路を更新しつつ誘導する。
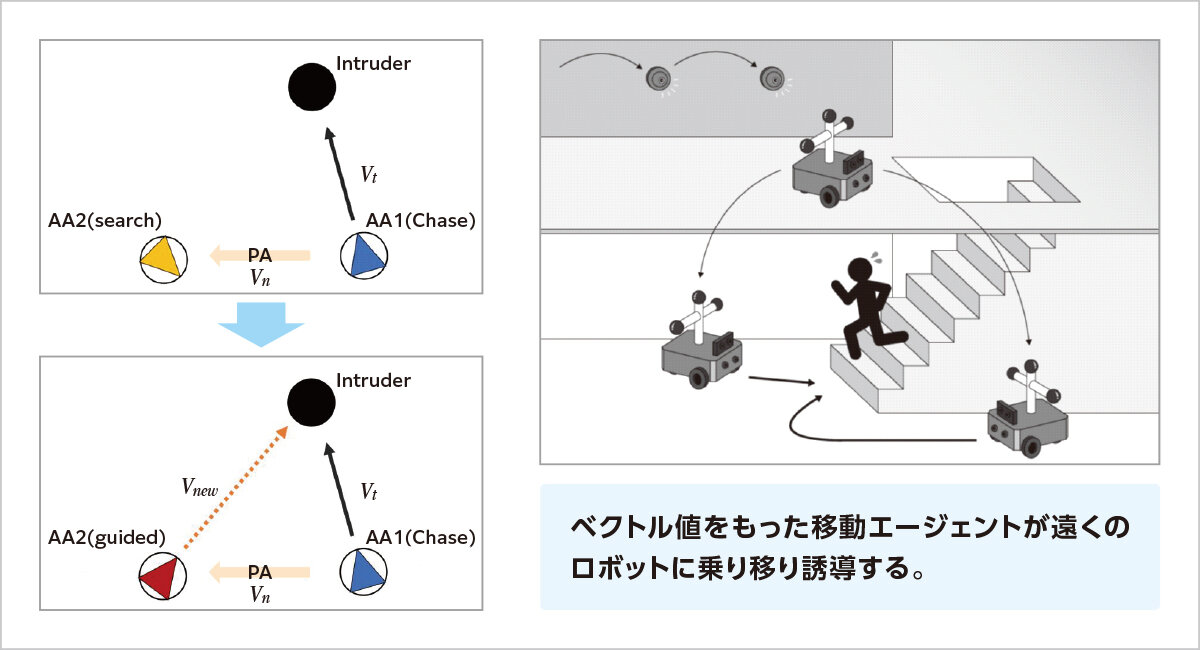
複数の小型移動ロボットが協働して侵入者を追い詰める。ロボットを操縦するエージェントは位置情報を交換しあいながら協調動作する。
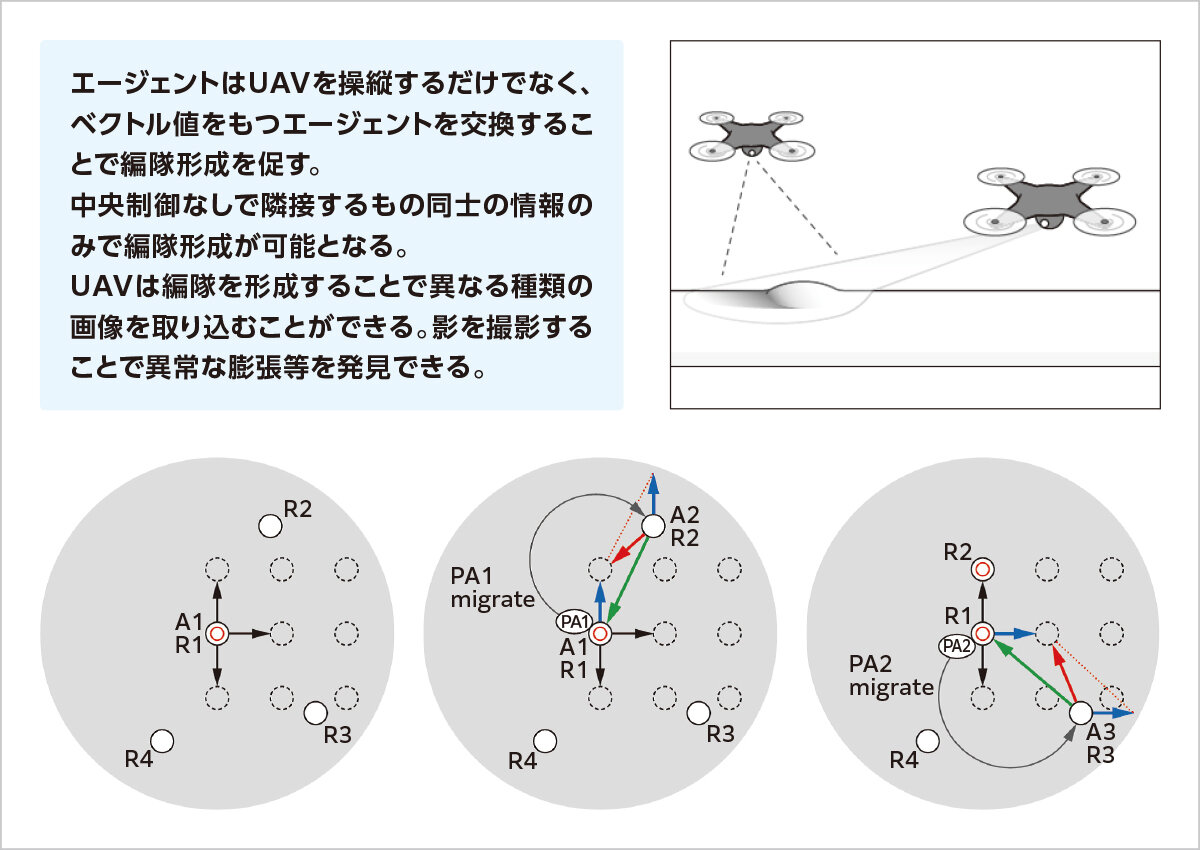
複数のUAVが編隊を組むことで構造物の異常を多角的に検査発見できる。

わたしたちは,ソフトウェアが正しく作られているかをコンピュータで自動的に調べる方法の研究開発を行っています.
現在は,人間が持つ経験的な知識を活用しながら,人工知能領域の研究で発展してきた様々な探索技術を応用して,無駄のない検査の実現を目指しています.開発者を支援技術の研究を通じて,ソフトウェアによるモノづくりに貢献 してきたいと思います.
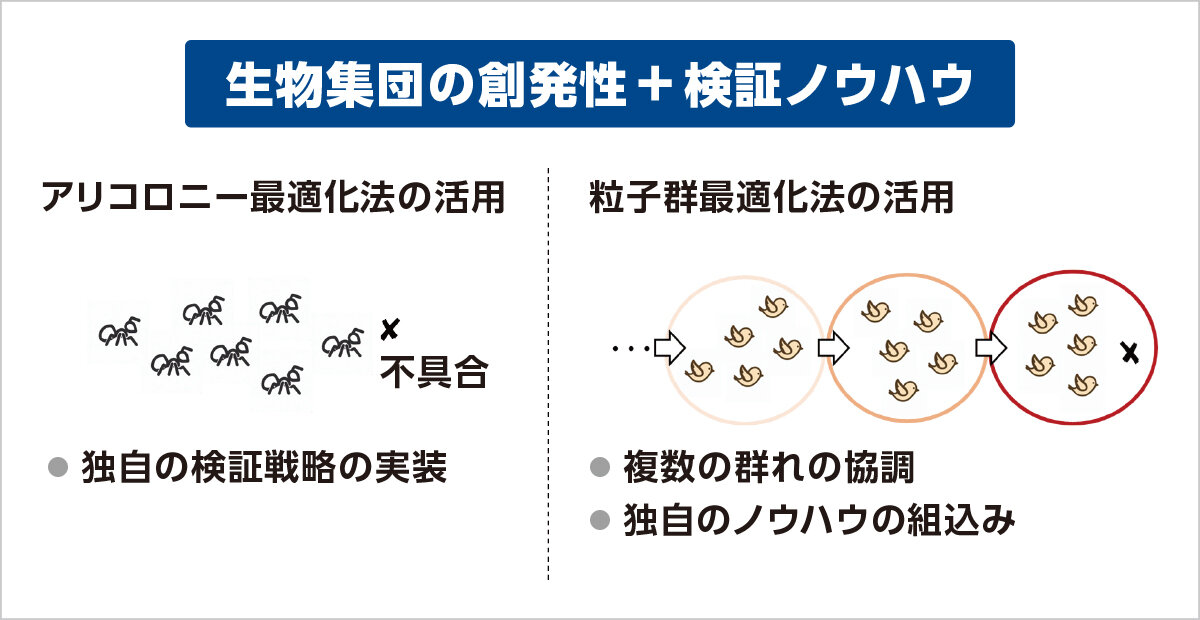
群知能は,多数のエージェントから成る群れを用いた探索技法です.わたしたちは,複数の群れが探索空間を分担することで,ソフトウェアに含まれるエラーを群知能で効率的に探す技術を開発しています.さらに,分かりやすいエラーの発見を目指し,複数の群れの活用に適した発見的方法の開発も行っています.
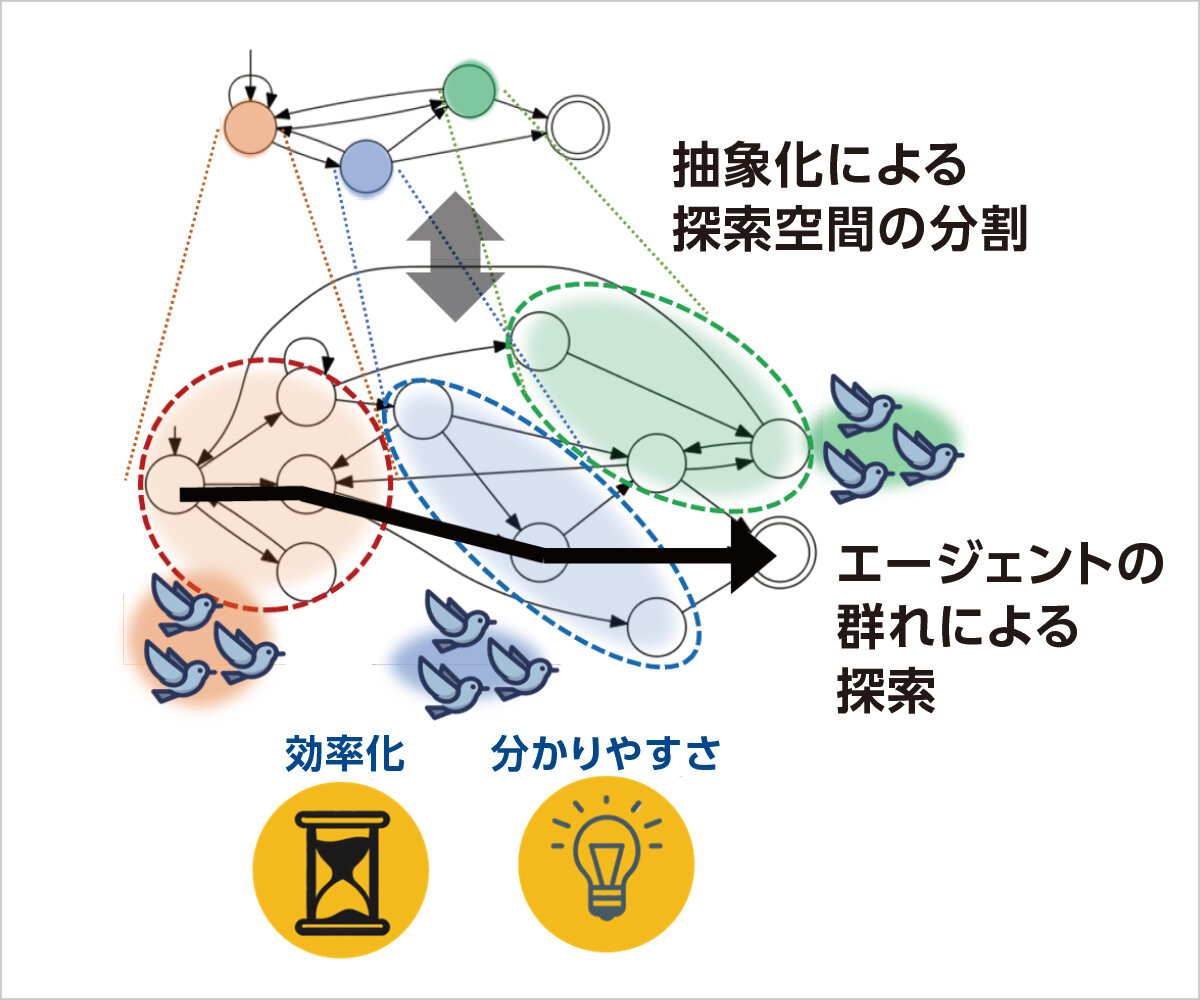
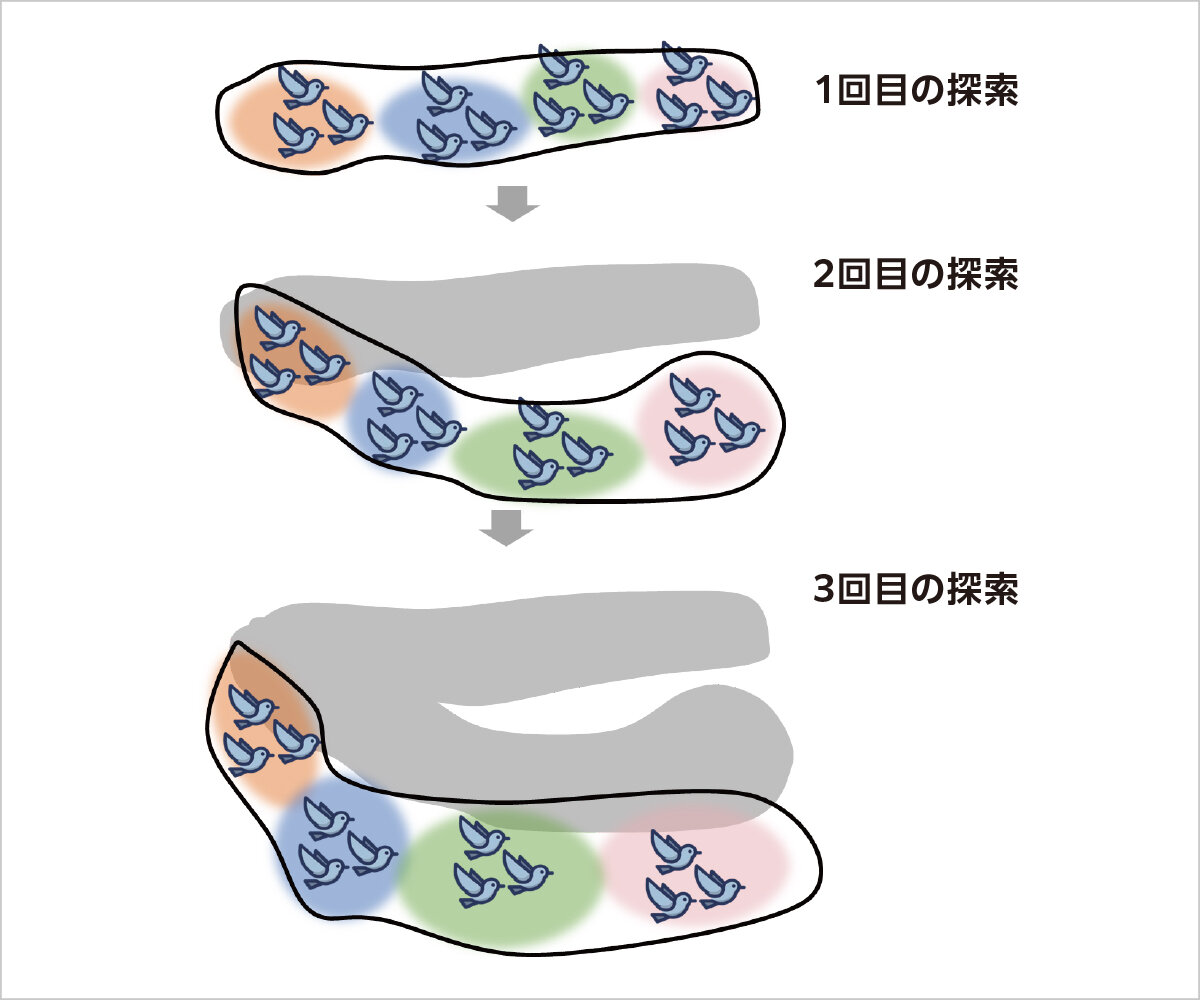
ユーザにとって分かりやすいエラーを探すためには,探索範囲を広くして,できる限り多くの場合を検査する必要があります.そこで,群知能による探索を繰り返し実行することで,探索範囲を効率的に拡大していく技術を開発しています.

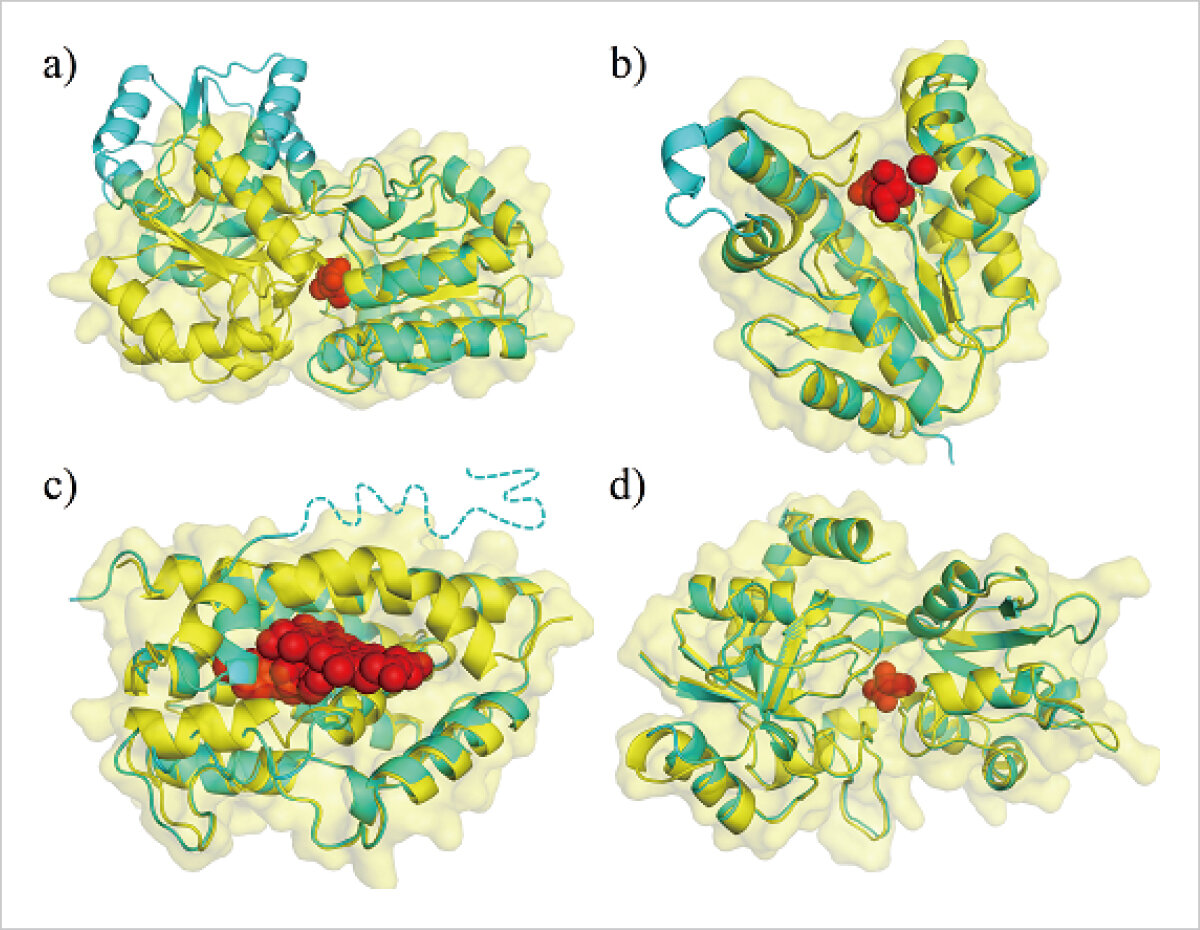
生命を情報科学(計算化学)の観点から眺め、複雑な生命現象を理論的に解き明かしていく研究をしています。特に、生体内に存在する様々な分子の挙動を、計算機でシミュレーションすることで、非常に小さい、そして早い動きを理論的に観察します。その分子の動きから、より効果的な薬や人工的な分子を計算化学的に設計します。
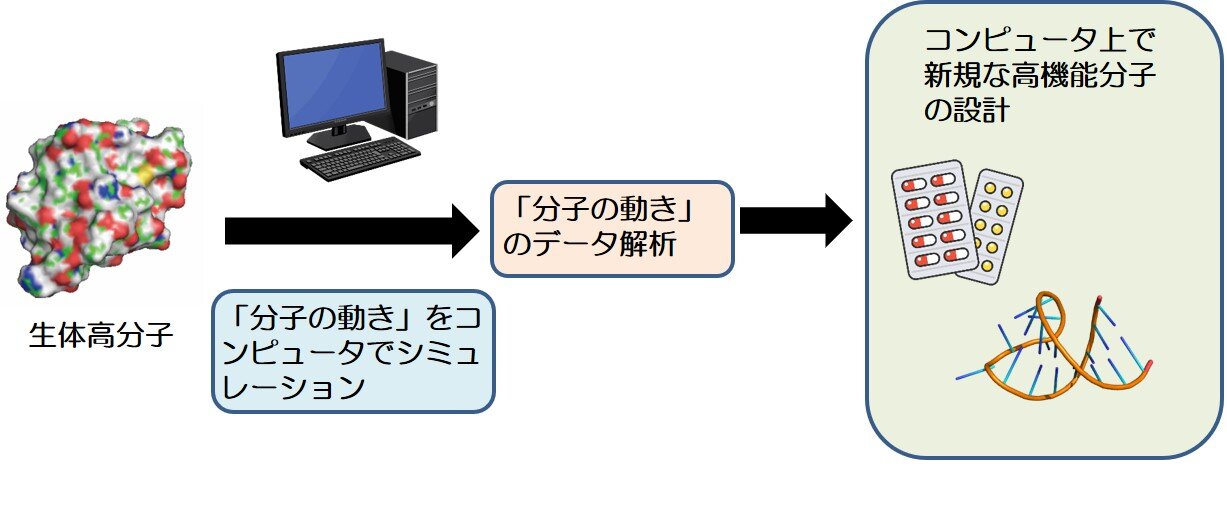
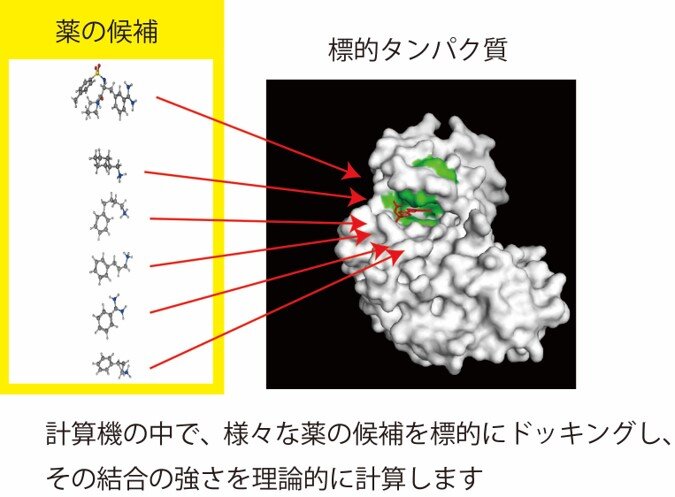
薬の候補となる化合物は、膨大な数があります。その候補となる化合物を、計算機(コンピュータ)の中で標的タンパク質にドッキングさせ、その結合の強さを分子シミュレーションや統計解析等で理論的に予測し、有力な薬の候補を絞り込みます。また、シミュレーションによるデータを活用し、より効果的な薬剤へと分子設計を行います。
RNAアプタマーとは、タンパク質などの標的分子に特異的に結合するRNA分子で、その特異性や結合力は抗体に匹敵します。また、抗体より安価に製造可能であり、近年は抗体医薬に代わる次世代分子標的薬として注目されています。 そのようなRNAアプタマーのデータベース構築や分子シミュレーションを行い、RNAアプタマー医薬品の効率的な創薬基盤技術の確立を目指しています。

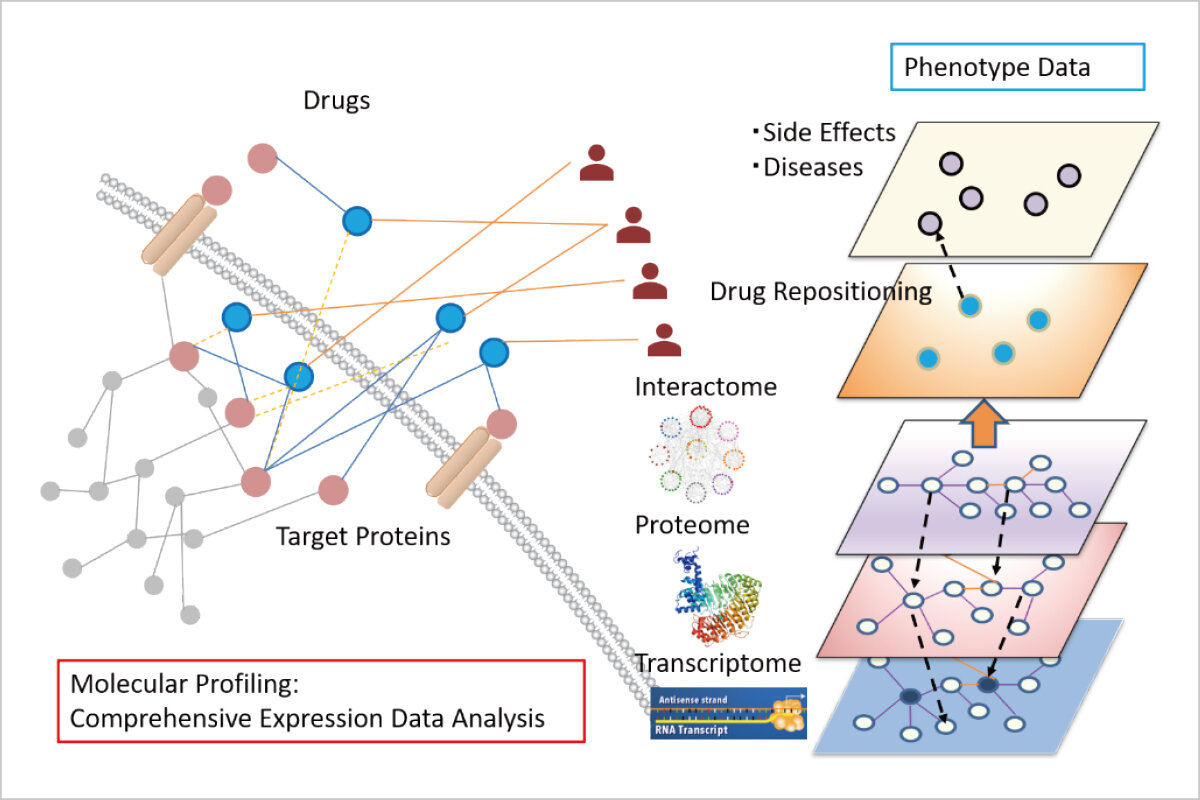
当研究室では、ライフサイエンスの研究分野において、様々な疾患の計測された分子プロファイリング情報をコンピューターで解析することで、要因となる分子や有効と考えられる薬剤候補を見つけ出す研究を行っています。
またヘルスケア情報における新しいタイプの ビッグデータとして、スマートフォンや生体センサーの普及により、健康に関する多様な生体情報が測定できるデジタルヘルス化が進んでいます。この研究では地域社会と連携し、分子情報とヘルスケア情報を組み合わせ、様々な数理情報解析を行いデータサイエンスによる未来型社会について考えます。
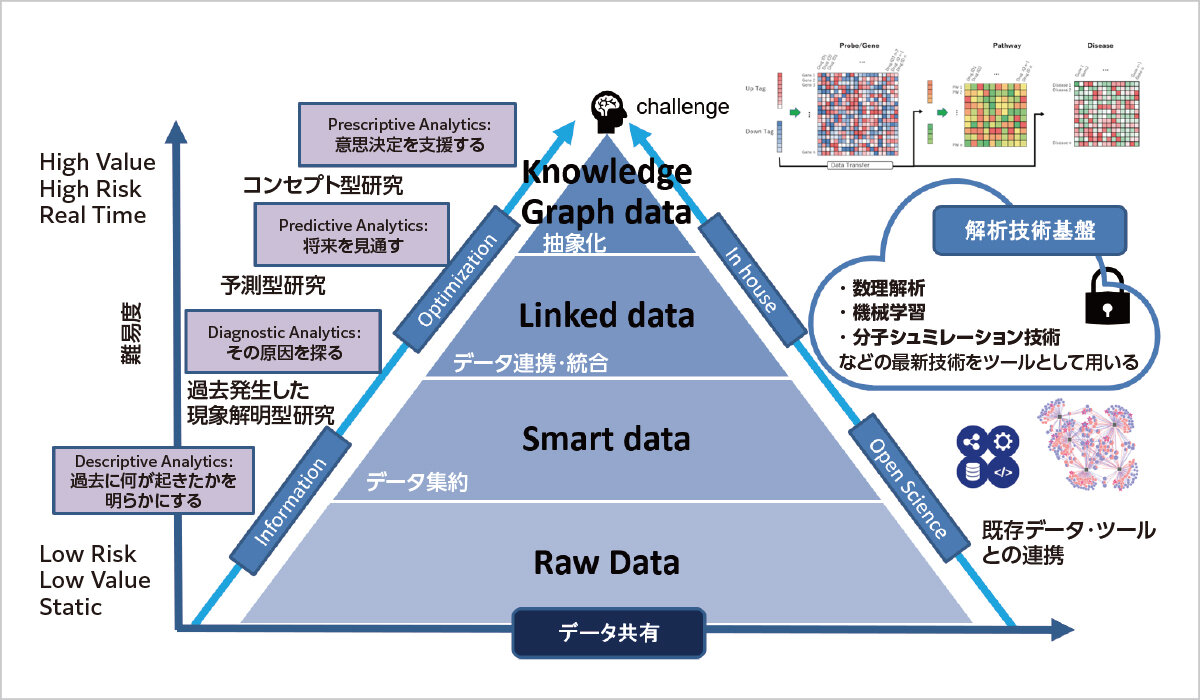
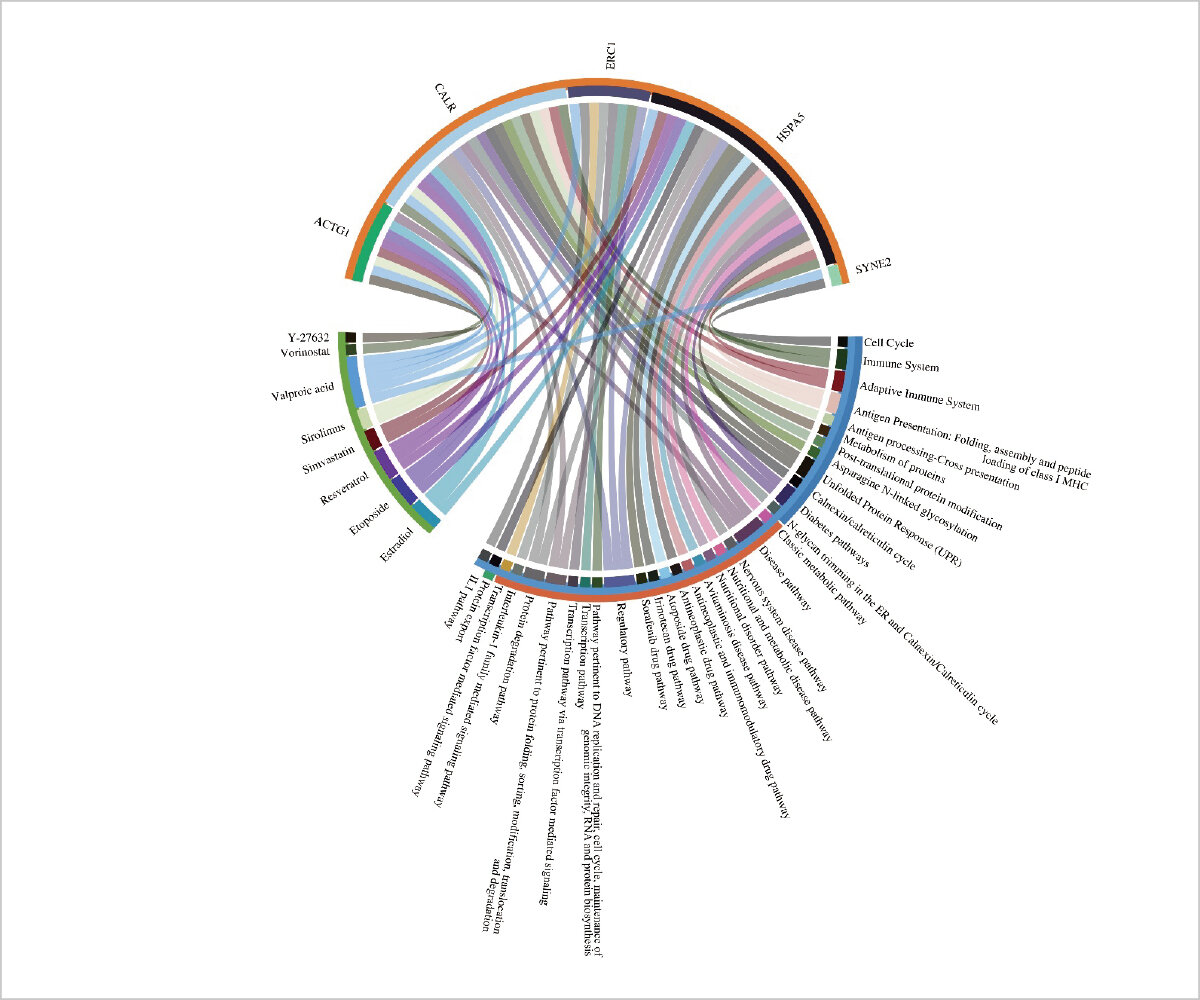
薬剤投与や刺激による細胞状態の変化を表す発現プロファイルデータや分子間相互作用ネットワークに基づいた多層解析による薬剤の絞り込みについて研究しています。 また、薬剤誘発性有害事象データベースとしてのFAERS( FDA Adverse Event Reporting System)や毒性データとの連携・統合により知識グラフやネットワークを活用した薬剤候補の選択など、生命を個々の分子に還元して理解するのではなく、総体としての系(システム)という観点から捉えるポリファーマコロジーによる研究を進めています。
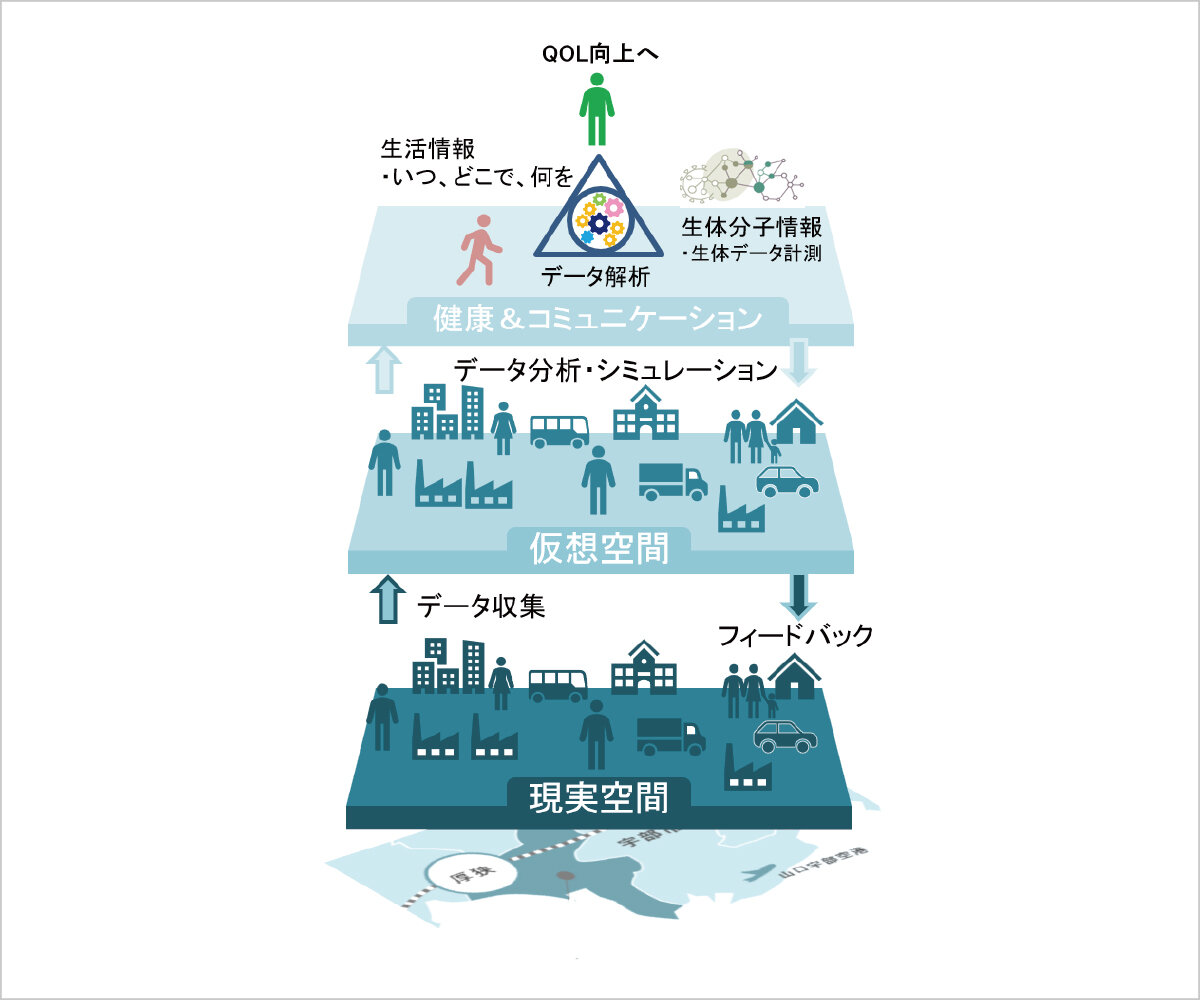
デジタル技術の深化に伴い、人々の暮らしや街づくりなどにデジタルデータの活用が大きく影響し、データサイエンスによる暮らしの利便性向上が非常に期待されています。この研究では地域社会と連携し、現実世界である層と仮想空間であるデジタル層を考え、その中から必要に応じて様々なレイヤーを抜き出し、数理情報解析に取り組んでいます。また産学官連携により、多くの人々を巻き込み、協調・連携した地域社会のありかたや社会課題について考えます。

地上型レーザスキャナなど様々なタイプの3Dセンサが次々と登場し,建築・土木から農業・林業まで,幅広い分野で利用されるようになり,実環境をそっくりそのまま計算機上に再現することが可能となっています.私の研究では,3次元計測により取得した点群を主な対象とし,点群中の環境・物体認識,及び点群からの高品質3Dモデル構築に関する技術開発を進めています.対象は土木構造物,建築物,産業プラント,道路,森林,公園等ですが,計算幾何やコンピュータ・グラフィクス等の3次元形状処理技術,及び数値計算や統計,機械学習といったデータサイエンス技術を駆使し,将来を見据えた基礎技術の開発から,民間企業や自治体と連携した応用研究まで,幅広く取り組んでいます.

実世界に存在する多種多様な環境や物体を,レーザ計測点群や画像から自動認識するための様々な研究開発を進めています.例えば,深層学習を活用した高精度樹種判別に関する研究では,レーザスキャナやカメラ等のセンサ,またUAV,ヘリ,バックパック等の搭載プラットフォームの特性を考慮し,取得される大量データの特徴を最大限活かすことで高精度化を目指す新たな技術開発を進めています.

土木構造物や建築物の維持管理のために,写真計測やレーザ計測により取得した点群から,3次元形状と属性情報を併せ持つBIM/CIM(Building/Construction Information Model)を自動構築する技術開発を行っています.特に,表面積の大きな基本構成要素だけでなく,土木構造物表面の微細な劣化や損傷,または建築物に取り付けられた小さな付属設備なども含めた,高詳細なBIM/CIMの自動構築を目指して研究を進めています.


公共データベースに登録されている生命科学に関する実験データを利用した創薬研究新規治療薬の開発にかかる膨大な費用を軽減するために、公共データベースに大量に保存されている生命科学データを利用した創薬の研究を行っております。実験技術の急激な進歩により、公共データベースに登録されている病気や薬の使用時の実験データも飛躍的に増加しました。このような世界中の公共データベースから病気や薬、薬の標的となるタンパク質に関するデータを抽出し、解析を行い病気に有効な薬を探しています。
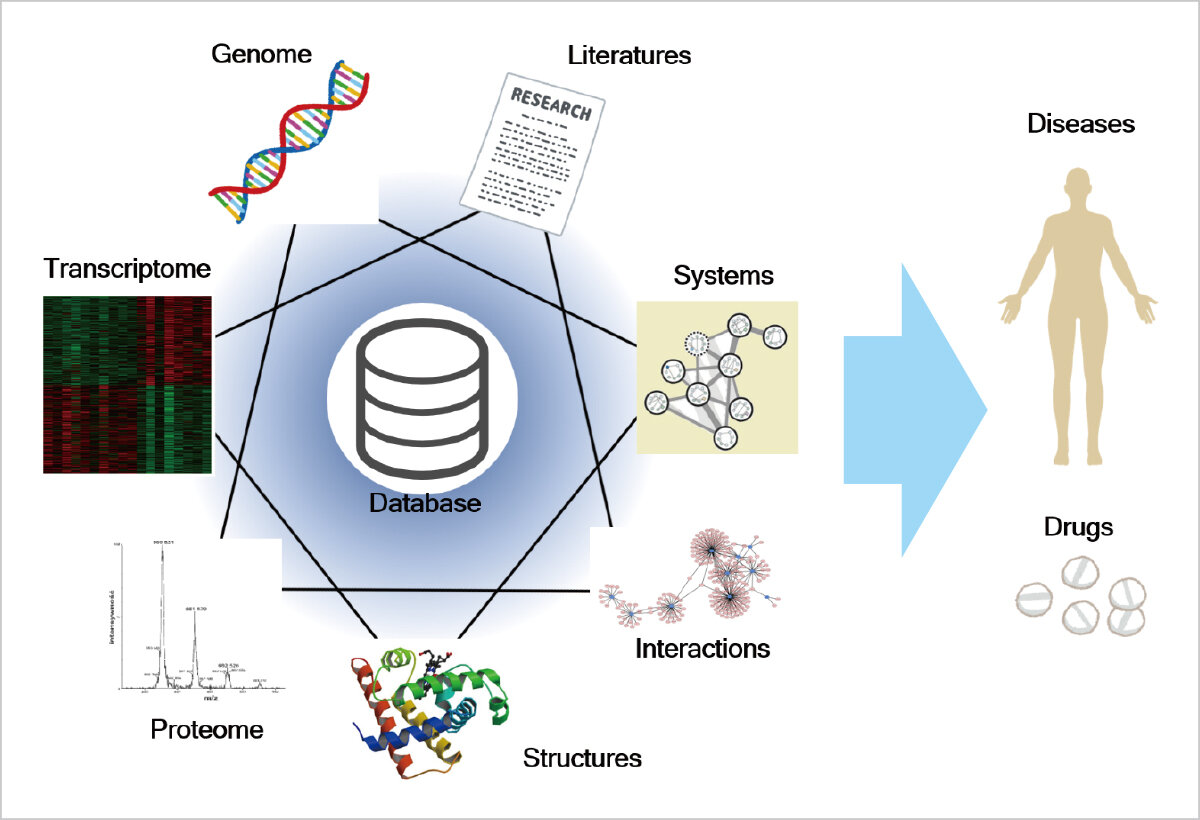
生命の体内に存在する分子をまとめた情報をオミックスといい、複数のオミックスに跨る解析をマルチオミックス解析といいます。一つのオミックス情報のみでは得られない情報や新しい医学的、生物学的知見を得ることができ、近年の大量データ集積によりマルチオミックス解析が実現可能になりました。多数の病状の実験結果から複数のオミックスデータを収集し、データベースを構築、統合的なマルチオミックス解析を行い、新規治療法や創薬につなげる研究を行っています。
生命の遺伝情報の産物であるタンパク質は合成プロセスや発現される機能より特異な立体構造をしています。世界の公共のデータベースにある大量のタンパク質の立体構造に関する情報を利用し、統計学的なモデルを適用して、タンパク質の立体構造と合成プロセスや機能との相関関係を明らかにすることで創薬研究や生命の理解に役立つことを目指します。

本研究室は、様々なデータ分析や自動化の問題に取り組んでいます。例えば、自動化タスクでは、膨大な量のデータが必要ですが、データはいつでも無尽蔵に集められるとは限りません。そのようなとき、データを増やしたり、データの代わりに数式で書かれた知識を深層学習に融合させ、本質を掴むことで、必要とするデータの量を減らしたりします。また、データや学習したモデルから知識を取り出す「説明性」の問題にも取り組みます。説明性向上タスクは、研究者が行っている研究活動の一部を自動化する試みです。 本研究室では、多様な応用問題に取り組み、マルチモーダルな人材育成を目指します。そのために、様々な団体・組織との共同研究を行い、学生や若手研究者育成のためのプログラムを推進します。

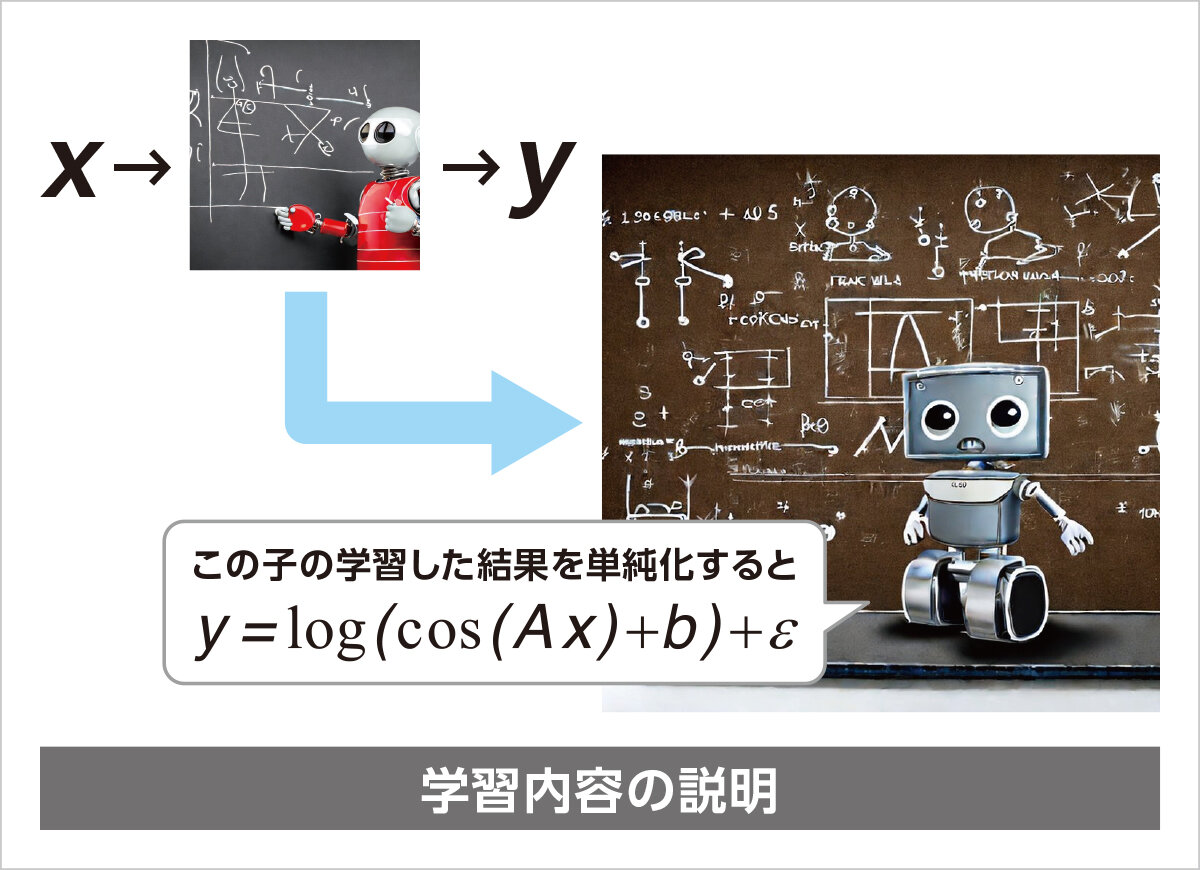
データから法則(関数やそれを解とする微分方程式)を獲得するホワイトボックスアプローチに関する研究は近年注目を集めています。記号回帰は計算量が膨大であるという欠点があり、ニューラルネットワークを用いたブラックボックスモデルアプローチは説明能力に乏しいです。非線形力学のスパース同定SYNDyは単純な形の解を求めることができるホワイトボックスアプローチとして注目されています。しかし、合成関数を辞書行列に登録する必要があり、組み合わせ爆発的な手間がかかる問題があります。そこで、いくつかの基礎となる関数や演算子と変数だけを辞書に登録し、合成関数の構造も含めた最も単純な(最も要素を使わない)表現を得る方法が必要です。この問題は関数同定問題、システム同定問題などの一種です。

膨大なデータを学習したモデルは、一つの多変量の関数としてみなすことができますが、人間がそのモデルを見て理解するようには設計されていません。そこで、関数同定問題、システム同定問題で蓄積した方法論を用いて、学習したモデルを人間が理解できる、より単純な形に翻訳して説明するための方法論を探索します。

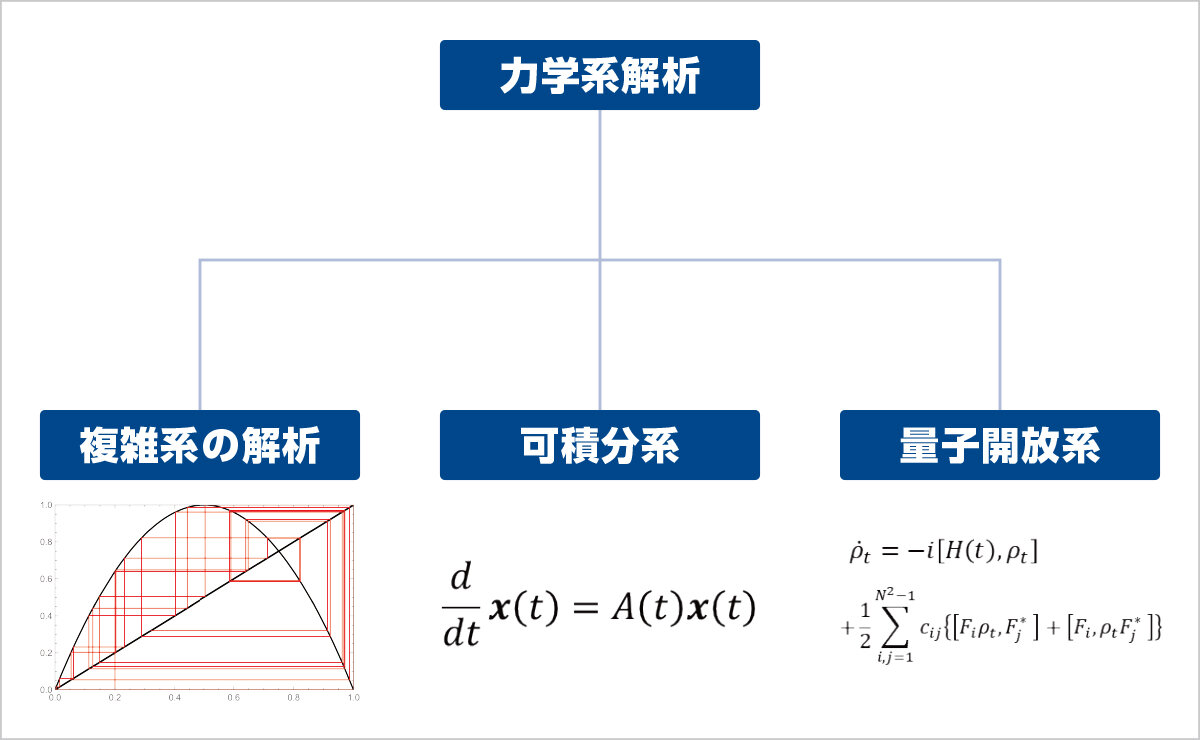
自然科学の様々な現象は、微分方程式や差分方程式といった数式で数理的に記述されます。この様な系を力学系と呼びますが、一般的に力学系の解析は非常に困難です。例えば「カオス」と呼ばれる非常に複雑な挙動を示す場合は解析を工夫をする必要があります。一方、一見複雑に見える微分方程式でも幾つかの部分に分解出来る場合があり、その場合は各々の部分だけ解析すれば良いので構造が簡単になります。これらを判断し詳しい解析をしようというのが本研究室の主な研究テーマです。
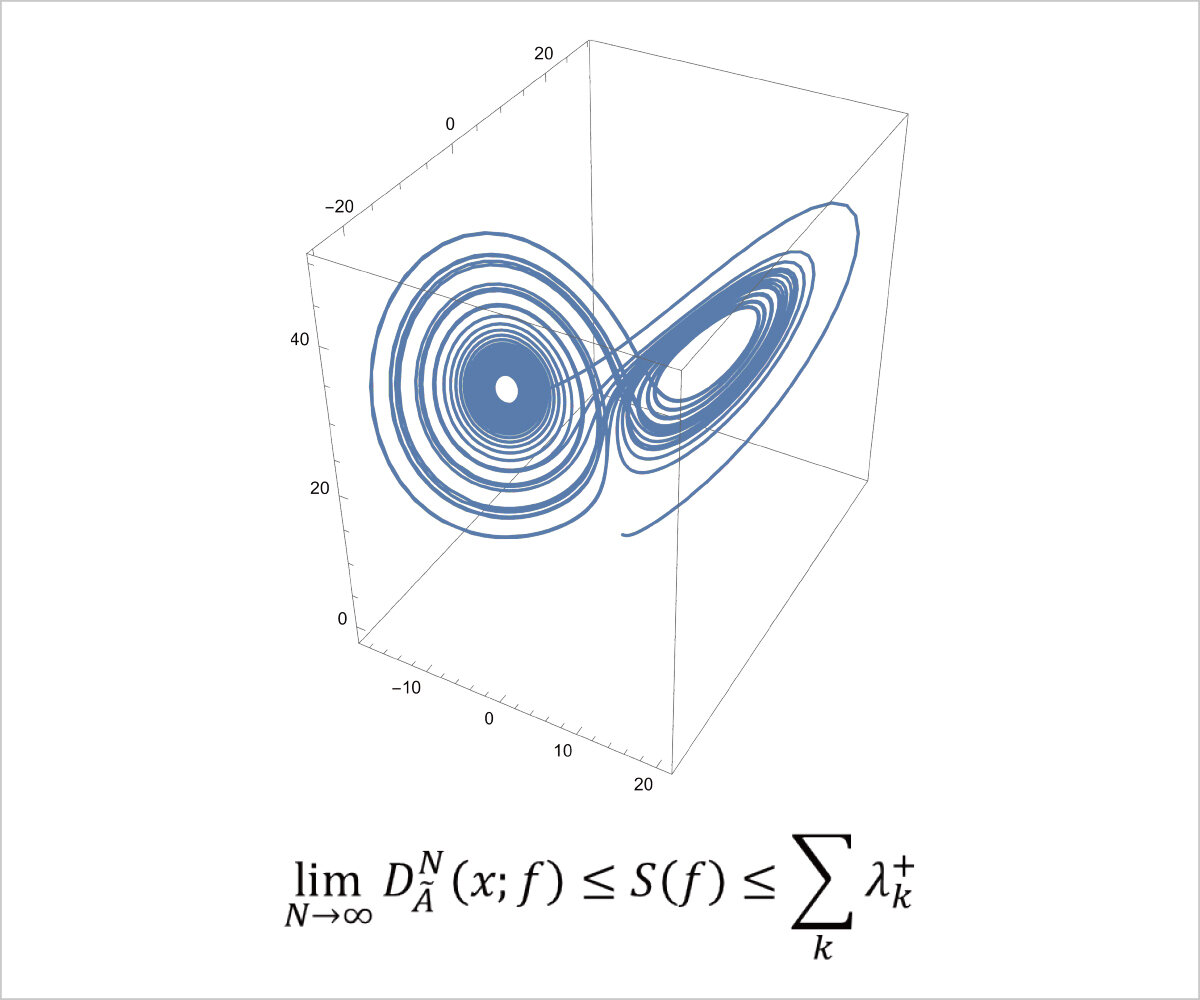
科学の様々な分野で用いられる数理モデルは、安定的な挙動を示す事もあれば複雑な挙動を示す事もあります。これを調べる為の指標が幾つか考案されており、様々な系の複雑さを調べるのに用いられていますが、未だに分からない事が多くあります。本研究室では、これらの指標がどの様な場合に安定的・カオス的と判断するのかを調べ、更にこれらの指標間の関係性について研究しています。

性別、職業、血液型のような数値化ができないようなデータが工学、薬学、マーケティングなど様々な分野で見られます。
このような数値化出来ないデータは質的データと呼ばれ、数的データと異なり「平均を取る」のような操作を行うことができません。そのため質的データの解析は数的データの解析とは異なるアプローチが必要となります。藤澤研究室では、 その中でも2種類以上の質的データを含むデータに対するデータ解析の方法論について研究に取り組んでいます。
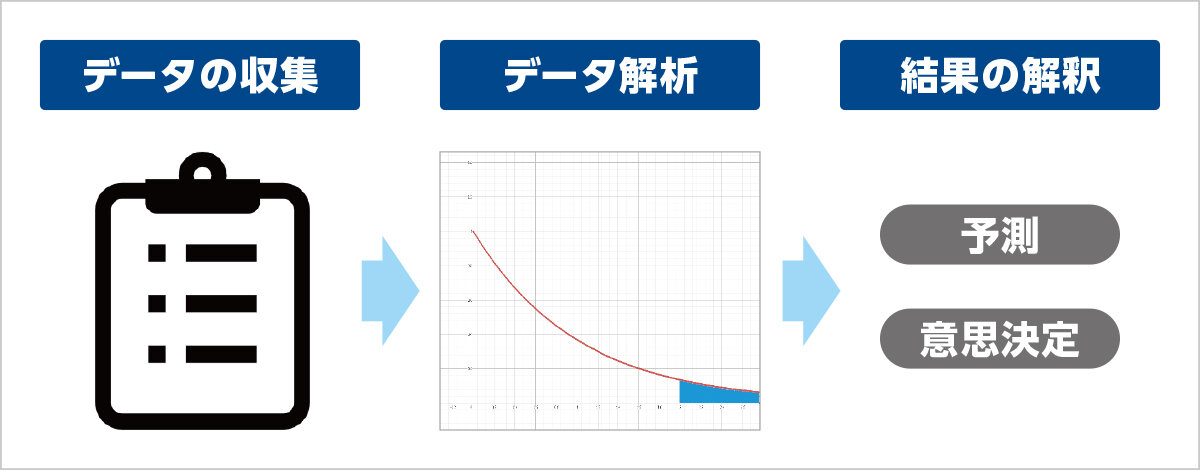
2つ以上の質的変数から構成される表形式のデータは分割表と呼ばれ、質的変数間の相互関係を分析するために利用されます。分割表解析に統計モデルを用いることで、変数間の相互関係の有無だけではなく、変数間にどのような関係が見られるかを特定することが可能になります。また、実際のデータが統計モデルに良く適合しているときは、より高い信頼度で推測が可能となります。
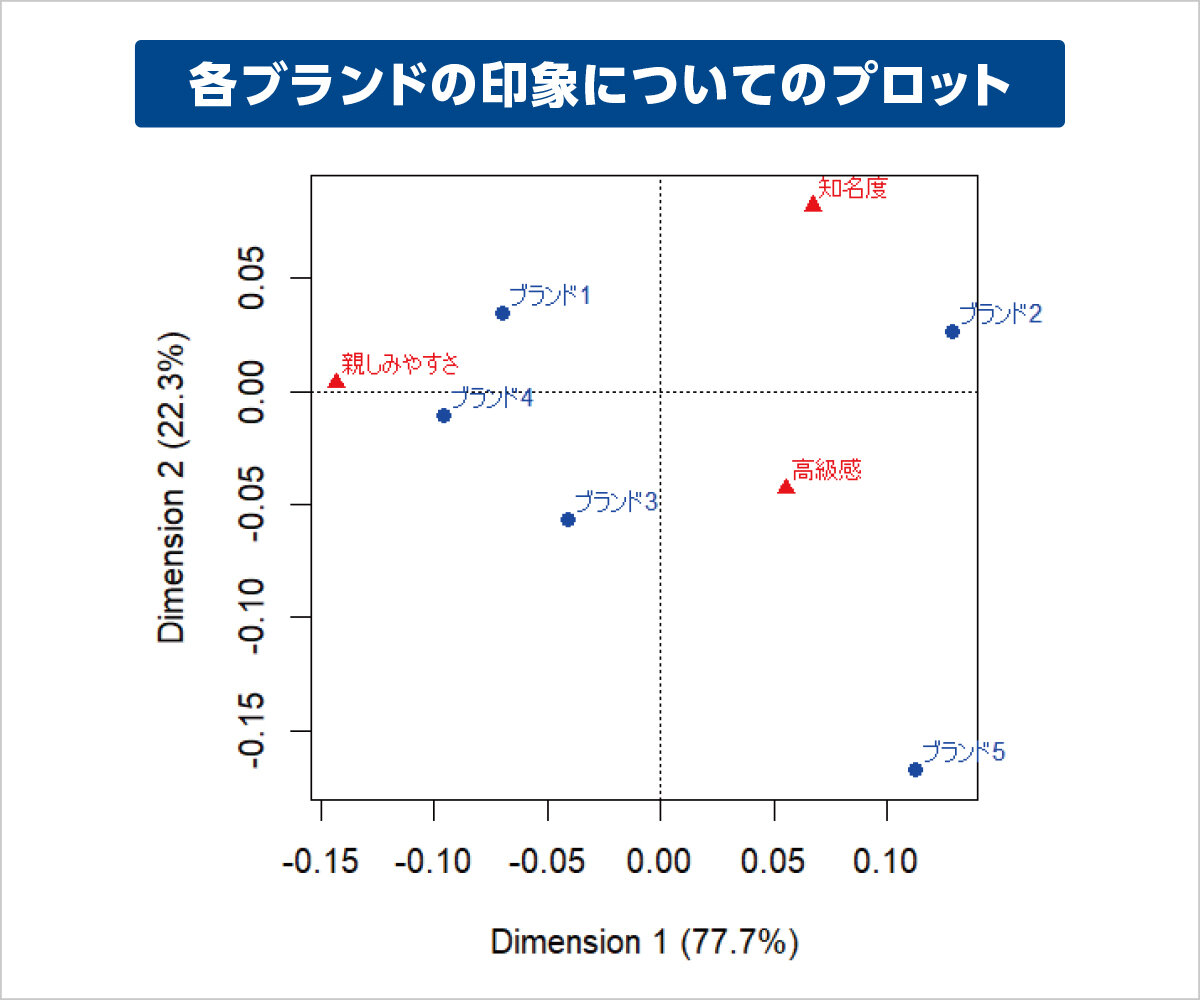
対応分析は質的データから構成される分割表を可視化するための多変量解析の手法の一つです。対応分析は質的変数を2次元の図にプロットし、変数間の類似性を距離を用いて視覚的に解釈することが可能になります。

我々は普段、10に基づく数の表記法を扱っています。私の研究では、この10進法を一般化して、1より大きい実数βに基づく数の展開の持つ性質や挙動について調べています。このような1より大きい実数βに基づく数の展開をベータ展開と呼びます。ベータ展開は暗号生成やシミュレーション、アルゴリズム等への応用が期待されている分野の一つとして知られています。例えば、ベータ展開は10進法に比べてランダムな数が発生しやすいことから、擬似乱数生成への利用が期待されています。他にも、Pisot数βにおいてはベータ展開の双対力学系とタイル張りが密接に関係しているため、タイリングによる画像処理やアルゴリズム最適化といった技術に応用できる可能性を持っています。

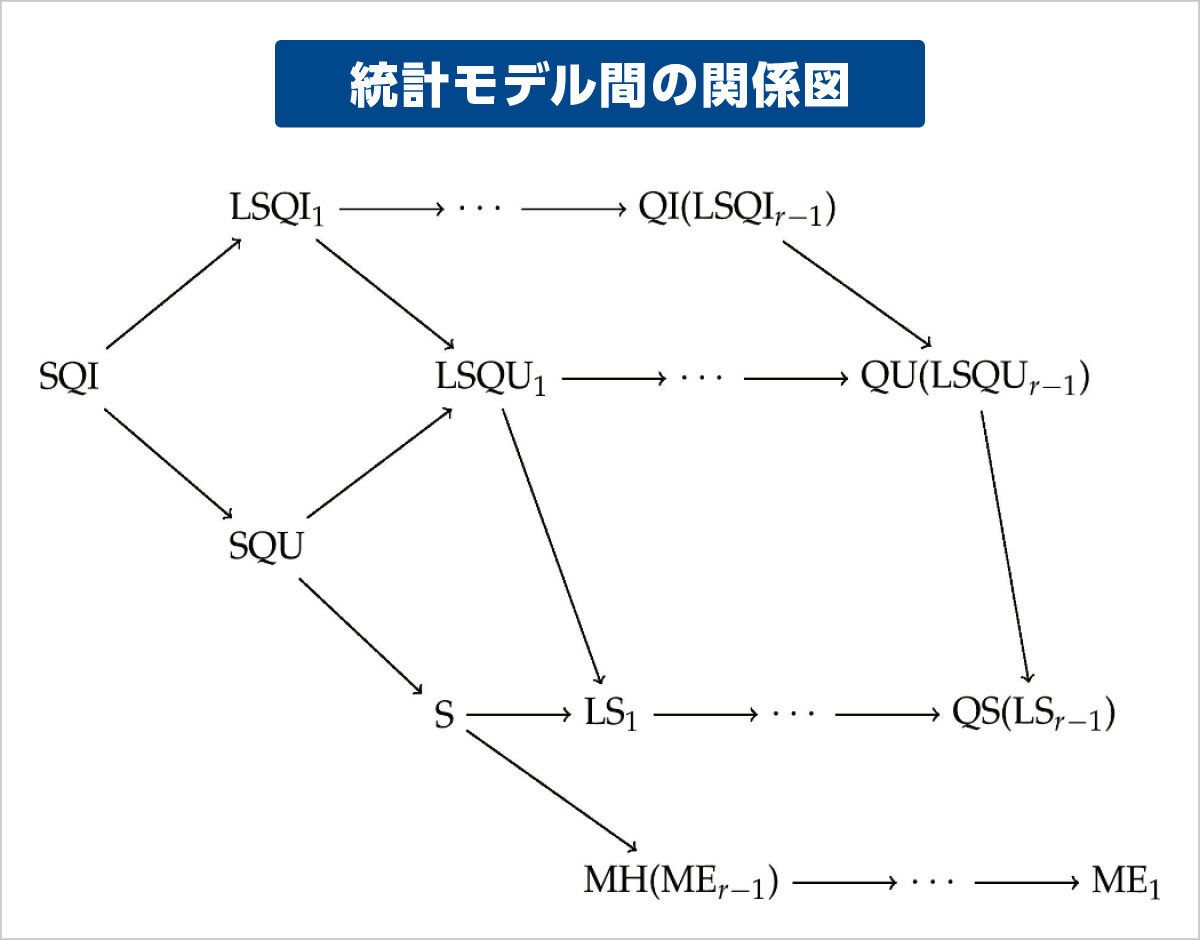
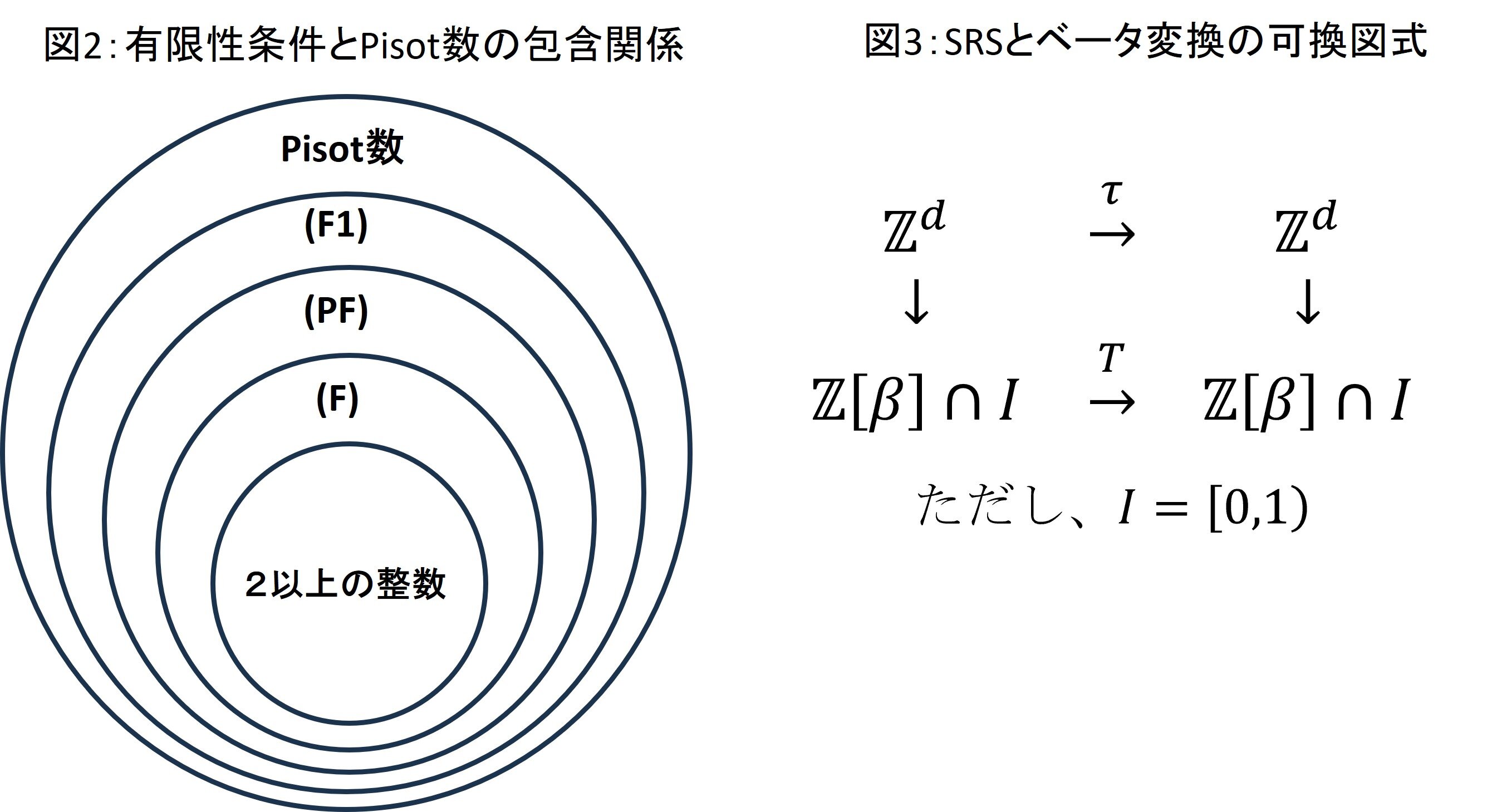
分母の素因数が2か5のみの有理数は有限小数となることが知られています。。この性質をβ>1に一般化したものを有限性条件といい、現在では(F)、(PF)、(F1)の3つが知られています。x < 1のベータ展開はβ変換T:x ↦(βxの小数部分)を利用して得られ、特に βがd+1次の代数的整数ならTの挙動はSRSと呼ばれるd次元格子上の変換の挙動として表現できます。私は、SRSと有限性条件について主に研究しています。
x ∈ [ 0,1) のベータ展開がx = a1 β-1+a2 β-2 ⋯であることをdβ(x)=a1a2⋯と表します。 ベータ展開に現れ得る有限部分語で生成された無限言語をベータシフトといいます。一般に、ベータシフトには「禁止語」と呼ばれる、どの有限部分語にも現れない有限語が存在します。禁止語の全体が正則言語となるβをParry数、さらにその禁止語が有限生成(有限型サブシフト)なら単純Parry数と呼ばれ、いずれも代数的整数となります。私は、このようなオートマトンを利用した類別にも興味を持って研究に取り組んでいます。